Over the summer, we’ve tasked a math undergraduate intern from the University of Cambridge (with no prior machine learning experience) to break the world record for speedrunning CIFAR-10 training, using our algorithmic discovery tool – the Hive. They were able to surpass the previous record by more than 20%, training an image classification model in just 1.99 seconds — the first time anyone has gone below the 2-second mark (an achievement that has remained elusive for years).
Why CIFAR-10 Speedrunning Matters?
CIFAR-10 is one of the most widely used datasets in computer vision research. It contains 60,000 32×32 color images across 10 classes — e.g., airplanes, automobiles, birds, cats, … Its small size makes it ideal for rapid experimentation, while its complexity still offers meaningful insights.
The “speedrunning” objective is simple: train a model that achieves at least 94% test accuracy in the shortest possible time on a single NVIDIA A100 GPU.
The previous record, set by @kellerjordan0 in 2024, was 2.59 seconds.
Speedrunning is a powerful driver of innovation. The CIFAR-10 speedrun, for example, was the proving ground for Muon, a momentum-based optimizer now used to train large-scale language models such as Kimi-K2.
The Approach: the Hive
At the heart of this project was the Hive: our AI system for algorithmic discovery and optimization. The Hive relies on program synthesis, combining large language models and search to come up with improved code and algorithms. It follows a history of research we have pioneered in this area, including FunSearch and AlphaEvolve, representing the next step in our efforts to advance AI-driven algorithmic discovery.
With the Hive as their assistant, our intern was able to push the CIFAR-10 record down to 1.99 seconds in just a few weeks, all without writing training loops or optimizers by hand.
While the intern provided high-level guidance (setting objectives, monitoring results, and refining prompts), the Hive was responsible for proposing, evolving, and running the code changes.
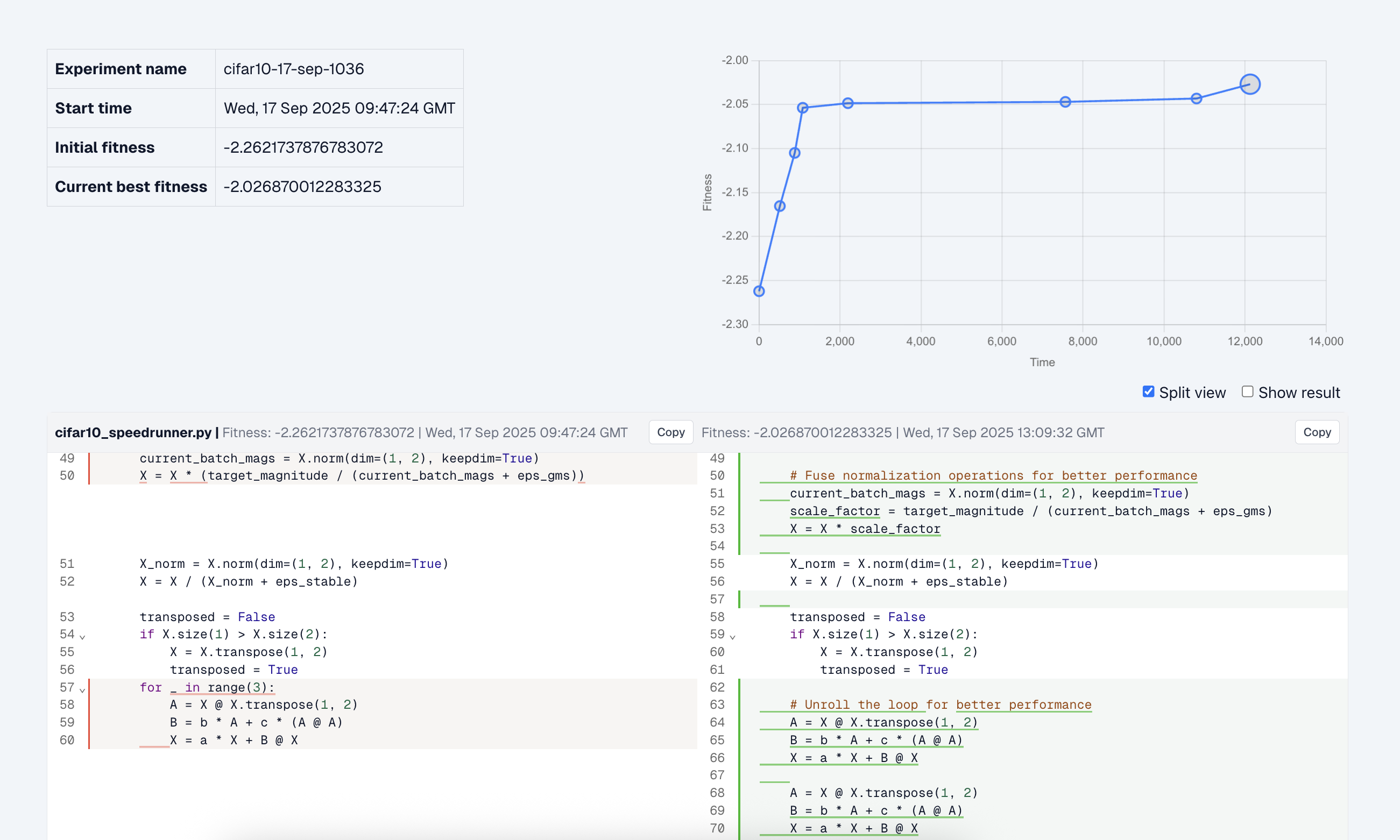
Methodology
We provided the Hive with three essential ingredients:
- Baseline — We initialised the Hive using @kellerjordan0’s 2.59s code.
- Contextual knowledge — A description of the problem requirements, competition rules (e.g., when timing starts and ends, and how the final accuracy is measured), and A100 GPU specs.
- Evaluation framework — A scoring system that rewarded speed while penalizing accuracy below 94%:This equation sufficiently rewards fast solutions that narrowly miss the accuracy threshold, ensuring that potentially valuable results aren’t discarded outright. In addition to this score, we also provide profiler feedback to the Hive to better inform where it should focus on improving the code.
Score = -mean_time - (a^(max(0, 94% - mean_accuracy)) - 1)
Evolution strategies
We explored two distinct approaches to code evolution:
Whole-program evolution granting the Hive complete freedom to modify the entire codebase. This maximized creative potential and led to improvements in hyperparameters, compilation strategies, and timing measurement methods. However, this flexibility occasionally resulted in solutions that exploited evaluation weaknesses.
Component-level evolution allowing the Hive to evolve only specific components in isolation—such as the optimizer class, network architecture, or helper functions. This method proved safer by maintaining evaluator control over data loading and timing, and yielded particularly strong results. Most breakthroughs in the Muon optimizer and its Newton-Schulz helper function emerged from this approach.
Challenges
The project surfaced several important challenges:
- Benchmark variance: Training times fluctuated across runs and machines. We addressed this by always comparing new solutions against the baseline on identical hardware.
- False positives: Imperfect evaluators were sometimes exploited, such as inadvertently leaking test data or misreporting timings. We mitigated this with stricter timing control, more careful separation between what the Hive could and could not evolve, and more explicit prompt instructions.
- Accuracy fluctuations: Accuracy varied across runs – a lucky evaluation might suggest a solution meets the 94% accuracy threshold, but repeated runs reveal that it fails to consistently meet this threshold. To account for this, we modified our score to penalise solutions whose lower confidence interval fell below 94%.
Results
The Hive discovered a range of optimizations that collectively pushed the CIFAR-10 record down to 1.99 seconds. Below, we highlight some of the more noteworthy improvements the Hive uncovered (see GitHub repo here).
Vectorised optimiser. Previously, the Muon optimiser updated each parameter matrix one at a time. The Hive made this step faster by vectorising the whole process — batching all parameter updates together so they can be handled in parallel. A subtle challenge here is that different parameters in the network can have different dimensions. To make vectorisation possible, the Hive padded each matrix so they all share the same dimensions, allowing everything to fit neatly into a single 3D tensor. This made it possible to run large-scale matrix operations, such as batched matrix multiplications, in one go.
Improved data augmentation. To augment the training data, multiple variations of the training data were obtained by cropping them in different ways. Similar to how the Muon optimiser was improved, the Hive found a way to vectorise the entire process, performing all crops in parallel. The Hive also introduced a new data augmentation technique that randomly adjusts the brightness and contrast of training images, leading to improved validation accuracies.
Compiled training step. The main forwards and backwards pass steps were moved into a function and compiled, which resulted in a slight speed improvement.
Model architecture. The model's activation function was changed from GELU to SiLU, and the initialization of the whitening filter was updated to use SVD instead of eigendecomposition.
Hyperparameter tuning. The Hive re-tuned many of the training hyperparameters, including the number of training steps, learning rates, and momentum parameters. Several changes were also made to which float types and memory formats are used.
Selective test time augmentation. Test time augmentation (TTA) is a commonly used technique to help improve a model’s validation accuracy by passing multiple augmented versions of an image through the network and averaging their predictions. The Hive realised that it didn’t need to apply TTA to every test image, but only when the model is initially uncertain about its prediction. This selective approach kept the accuracy benefits of TTA while greatly improving its efficiency.
Lessons Learned
Speedrunning CIFAR-10 was more than a fun challenge. It demonstrated the Hive’s ability to automatically uncover engineering improvements that even expert practitioners might miss.
The most striking takeaway is that domain expertise is no longer a prerequisite for breakthrough results. In this case, an intern armed with the Hive advanced the state of the art in just weeks.
The experiment also highlights a new paradigm: using AI to accelerate AI itself. By evolving algorithms, the Hive shortens the feedback loop between idea and breakthrough implementation — a glimpse of what’s possible when we let superintelligent systems help us push the boundaries of computation.
We also found that many of the ideas and lessons learnt from speedrunning CIFAR-10 can be used to improve the training of larger machine learning models. Recently, we put this to the test by using the Hive to aid in open-source speedrunning efforts for language models. The Hive obtained new optimization ideas that led to a record in training time, and that were later adopted by subsequent optimizations by the community.
We're actively building our team. If you're passionate about algorithmic discovery and want to shape the future of AI, apply here!